Токены и контекст в ИИ: объяснение простыми словами
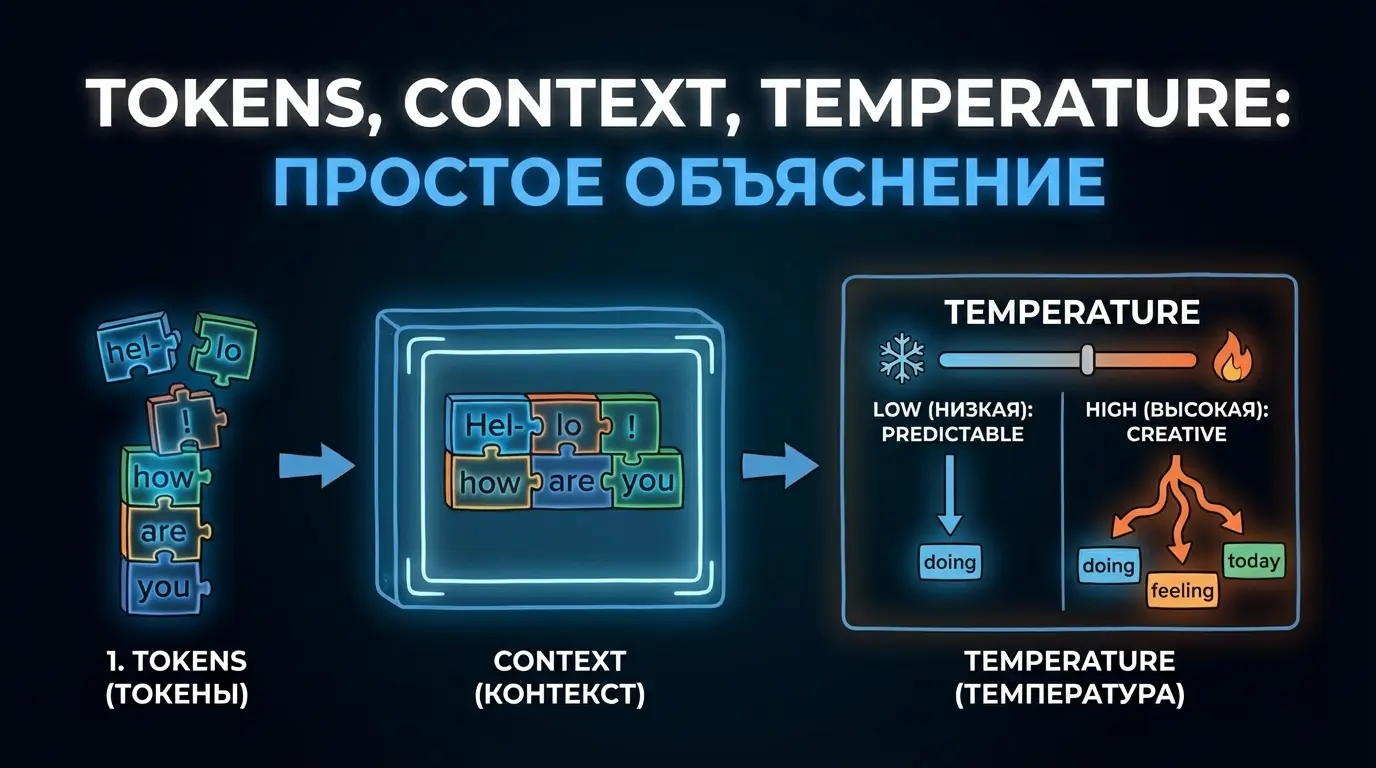
Токены — из чего ИИ «складывает» текст
Представьте, что язык для модели — это не слова целиком, а коробка с кубиками LEGO. Из них она и собирает фразы: подбирает следующий «кубик» так, чтобы получилось похоже на нормальную речь. Эти кубики и называются токенами — маленькие кусочки текста, из которых ИИ строит ответ.
И важный момент: токен — это не всегда слово. Иногда это часть слова, отдельный знак препинания или даже пробел. То есть модель может видеть текст как набор фрагментов вроде “привет”, “,” и “ ” (пробел), а не как аккуратные слова из учебника.
Примеры (условно, как это может выглядеть):
-
«Привет, мир!» →
Привет,мир! -
«переписка» →
переписка(да, слово может порезаться на части)
Из-за этого почти все лимиты — на длину запроса и ответа — обычно считают в токенах, а не в символах. Поэтому две фразы одинаковой длины “по буквам” могут занять разное количество токенов.
Контекст — «полоса внимания» модели
Контекстное окно — это, по сути, сколько текста модель может держать «перед глазами» одновременно. Мне нравится метафора со столом: представьте, что вы разложили на столе бумаги с перепиской. Пока места хватает — всё видно, можно листать глазами туда‑сюда и не терять нить. Но стол не бесконечный. Если документов становится слишком много, вы начинаете сдвигать старые листы на пол или в ящик. Они не исчезли из мира, но на столе их уже нет — и модель на них опереться не может.
И важный момент, который часто упускают: в контекст попадает не только ваш текущий вопрос. Туда же входят системные инструкции (вроде «будь вежливым», «пиши по-русски»), ваши предыдущие сообщения и ответы самой модели. То есть контекст — это общая «история разговора», которую модель держит в рабочей памяти. Например, если у модели контекстное окно условно на 8 000 токенов (это где-то несколько тысяч слов, очень грубо), то длинный диалог на 20–30 экранов легко его переполнит.
На практике это выглядит так: вы в начале беседы говорите «в моём проекте персонажа зовут Марк, он врач», потом час обсуждаете детали, и где-то ближе к концу спрашиваете «а что Марк делал в третьей сцене?». Если первые реплики уже «вытеснились» из окна, модель может начать путаться — назвать героя Максом, сделать его юристом или просто ответить слишком общо. Не потому что она вредничает, а потому что нужный кусок текста буквально не помещается в её «полосу внимания».
Почему модель иногда «забывает» и путается — это не каприз
Когда переписка становится слишком длинной, у модели просто не помещается в «голове» всё сразу. И она начинает выбирать: что-то свежее остаётся, а старые куски тихо отваливаются по дороге. В итоге теряются мелкие детали — имена, цифры, оговорки вроде «только без шуток» или «в рублях, не в долларах». А дальше начинается типичная каша: модель может повторять одно и то же разными словами, внезапно противоречить сама себе или “забыть”, что вы уже решили пару сообщений назад.
Это особенно заметно в задачах, где важны ограничения. Например, вы десять минут обсуждали структуру статьи, а потом в конце добавили пару новых требований — и модель внезапно пишет как раньше, будто этих требований не было. Не потому что вредничает, просто при переполнении контекста она опирается на то, что видит прямо сейчас, а не на всю историю целиком.
Что помогает (прям простые привычки):
-
Коротко пересказывайте важное по ходу: “Итого: пишем в 3 абзаца, тон разговорный, без терминов, примеры с цифрами”.
-
Закрепляйте требования в конце последнего сообщения — там, где модель точно их “увидит”.
-
Просите «сводку фактов»: “Собери список того, что уже утверждено, и не добавляй нового” — и потом опирайтесь на этот список.
-
Давайте структуру: заголовки, пункты, “вводная → пример → вывод”. Меньше шансов, что ответ расползётся и начнёт сам себе мешать.
Temperature — ручка «предсказуемость ↔ фантазия»
Temperature — это как термостат у модели: вы задаёте, насколько ей “греть” варианты ответов. Низкая temperature — и она играет осторожно, выбирает самые вероятные слова, поэтому ответы получаются более ровные, повторяемые и в целом надёжные. Иногда даже слишком: формулировки могут быть скучноватыми, а стиль — «как по методичке». Высокая temperature — и модель уже больше импровизирует, как джазмен: может выдать неожиданную метафору, нестандартный ход мысли, несколько разных способов сказать одно и то же. Но да, вместе с этим растёт шанс ляпов, странных утверждений и просто “заносов”.
Если нужны ориентиры (они примерные и зависят от модели):
-
0–0.3 — максимально предсказуемо: инструкции, факты, код, краткие ответы.
-
0.4–0.8 — золотая середина: нормальная живость без сильного хаоса.
-
0.9+ — много разнообразия: идеи, креатив, тексты «с характером», но проверять придётся чаще.
Короче, temperature — это не «умнее/глупее», а насколько смело модель выбирает слова.
Как выбрать temperature под задачу: три бытовых сценария
Представьте, вы спрашиваете у модели: «Составь пошаговую инструкцию, как вернуть товар по закону, и напиши в строгом юридическом тоне». Тут я бы ставил низкую temperature (примерно 0–0.3): ответ обычно получается ровный, аккуратный, без “творческих” прыжков и лишних украшательств — чего ждать: максимум конкретики и повторяемости, почти как по чек-листу. Риск: текст может звучать сухо и местами чересчур уверенно, а если в исходных данных дырка — модель так же уверенно её “закроет” формулировкой, которая выглядит правдоподобно, но может быть неточной.
А теперь другая сцена: вы вечером дописываете письмо клиенту или правите абзац в статье — чтобы было человечески, без канцелярита, но и без цирка. Ставите среднюю temperature (примерно 0.4–0.7) и просите: «Сделай мягче тон, сохрани смысл, добавь пару понятных примеров». Чего ждать: текст станет живее, появятся удачные переформулировки, но структура останется узнаваемой. Риск: модель может чуть-чуть “улучшить” факты или сместить акценты — вроде незаметно, но смысл уже не на 100% ваш.
И третий сценарий — когда нужен разгон: «Накидай 20 вариантов слогана для кофейни у метро» или «Придумай три концепции для рекламы». Тут уже просится высокая temperature (примерно 0.8–1.2): пусть шатает, пусть пробует странные ходы — иногда именно там и сидит золото. Чего ждать: много неожиданных вариантов, каламбуров, смелых образов, из которых можно выбрать пару реально цепляющих. Риск: вместе с креативом полезет шум — банальности, нелепицы и идеи, которые звучат ярко, но в реальности вообще не работают или не подходят бренду.
Мини-шпаргалка: как получать лучшие ответы без магии
Представьте, что вы говорите с помощником. Контекст — это папка с бумагами, которые вы ему выдали, а temperature — это инструкция “импровизируй или действуй строго по регламенту”. Если папка пустая — он начнёт угадывать. Если вы дали нужные документы и чётко сказали, как работать, магия внезапно превращается в нормальный процесс.
-
Следи за длиной (токены). Чем длиннее запрос и переписка, тем больше “съедается” лимит контекста. Если тема большая — режь на части: “сначала план, потом пункт 1, потом пункт 2…”. И да, лишние лирические абзацы в запросе часто просто мешают.
-
Держи важное в контексте. Ключевые условия лучше повторить прямо в конце: “важно: аудитория — новички, тон — спокойный, не больше 200 слов, примеры обязательны”. Модель не телепат, она опирается на то, что видит сейчас.
-
Проси формат ответа. Это реально половина успеха: “дай списком”, “таблица 2×4”, “структура: тезис → пример → вывод”, “в конце — чеклист”.
-
Temperature для творчества/точности.
-
Хочешь идеи, метафоры, варианты заголовков — повышай (условно
0.8–1.2). -
Нужна аккуратность, краткость, меньше фантазии — понижай (
0.1–0.3).
-
-
Мини-формула запроса: цель → контекст → ограничения → формат → уровень импровизации. Например: “Сделай 5 вариантов поста. Тема такая-то. Условия: без клише, 120–150 слов. Формат: нумерованный список. Temperature повыше.”
Решайте любые задачи с помощью ИИ — от генерации текста до создания изображений и видео.
Текст и код
Генерация контента, перевод, анализ данных и автодополнение кода.
Изображения, видео и музыка
Создание иллюстраций, видеоконтента и уникальных треков любого жанра.
Диаграммы, графики и схемы
Визуализация данных, построение графиков и генерация блок-схем.
Личный кабинет
-
Приоритетная обработкаЗапросы от пользователей личного кабинета обрабатываются в первую очередь
-
Бонус за регистрациюСтартовый бонус на счёт личного кабинета (~20 запросов), без регистрации - 3 запроса
-
Все передовые нейросетиВ личном кабинете представлен широкий выбор нейросетей (120+).
-
Генерация реалистичных изображенийMidjourney 6.0, Stable Diffusion XL, Dall-E 3, Playground v2.5, Flux.1 Schnell, Flux.1 Dev, Flux.1 Pro, Flux.1.1 Pro, Kolors, Recraft v3, GPT Image 1 (low), GPT Image 1 (medium), GPT Image 1 (high), Google: Nano Banana, Google: Nano Banana Pro, FLUX.2 Flex, FLUX.2 PRO, FLUX.2 MAX, Google: Nano Banana 2
-
Создание музыкиНейросеть Suno создает музыку на основе вашего текста
-
Нет ограничения на количество символовБез регистрации вы можете отправить запрос не более 1000 символов
-
Работа с файламиПоддержка всех популярных форматов: pdf, excel, word, powerpoint, odt, c, js, php, py, html, sql, xml, yaml, markdown, txt, json, csv, png, jpeg и другие
-
Удобный вспомогательный чатНа всех страницах проекта, для получения быстрых ответов
