Самопроверка ИИ: что такое Self-Consistency простыми словами
- Когда «умная» модель уверенно говорит ерунду: мини-разбор факапа
- Трюк «10 черновиков в стол»: что такое self-consistency по-человечески
- Как заставить модель перепроверять себя на практике: рецепт без магии
- Где это реально спасает: задачи, у которых есть один правильный ответ
- Где всё ломается: когда большинство — не умнее, а просто громче
- Как пользоваться без самообмана: маленькие страховки и здравый смысл
Когда «умная» модель уверенно говорит ерунду: мини-разбор факапа
Всё началось очень буднично: я сижу поздно вечером, допиливаю табличку с бюджетом на небольшую рекламную кампанию. Ничего героического — пару строк про НДС, пару строк про комиссию, итоговая сумма. Чтобы не тупить, кидаю ассистенту: “Посчитай, пожалуйста, финальную стоимость: 240 000 + 12% комиссия + 20% НДС, и покажи формулу”. Он отвечает идеально. Прямо как из учебника: аккуратные шаги, пояснения, даже фраза “итого к оплате”. И цифра в конце — красивая, ровная, уверенная.
И я бы почти отправил это в оплату. Почти.
Спасла одна мелочь: в табличке у меня итог не сходился на какие‑то жалкие 4 800 рублей. Не “вау, всё сломалось”, а ровно настолько, чтобы можно было подумать “ну, округления”. Я полез проверять — и обнаружил, что модель на автомате начислила НДС на сумму с комиссией, хотя по нашему договору НДС считался иначе (комиссия отдельно, НДС — на базу). Ответ звучал убедительно, но он был не “проверенный”, а просто хорошо сформулированный. Уверенный тон — это стиль, а не гарантия.
Вот в этом и проблема: модель может говорить гладко и без пауз, потому что она умеет строить правдоподобные тексты. Но “правдоподобно” не значит “правильно”. И если ошибка не на уровне “2+2=5”, а на уровне единиц, дат, условий договора или того самого “на что начисляется процент”, то она легко проскочит — особенно когда ты сам устал и хочешь довериться ответу, который звучит профессионально.
Поэтому и нужен способ заставить модель перепроверять себя. Не в стиле “ты уверен?”, а так, чтобы она реально прогнала несколько вариантов, сравнила их, нашла противоречия и подсветила места, где чаще всего всё ломается. Потому что факапы почти никогда не выглядят как факапы. Они выглядят как аккуратный абзац “как из учебника” — пока не заметишь, что сдача не сходится, дата не та, или вдруг рубли превратились в доллары где-то по дороге.
Трюк «10 черновиков в стол»: что такое self-consistency по-человечески
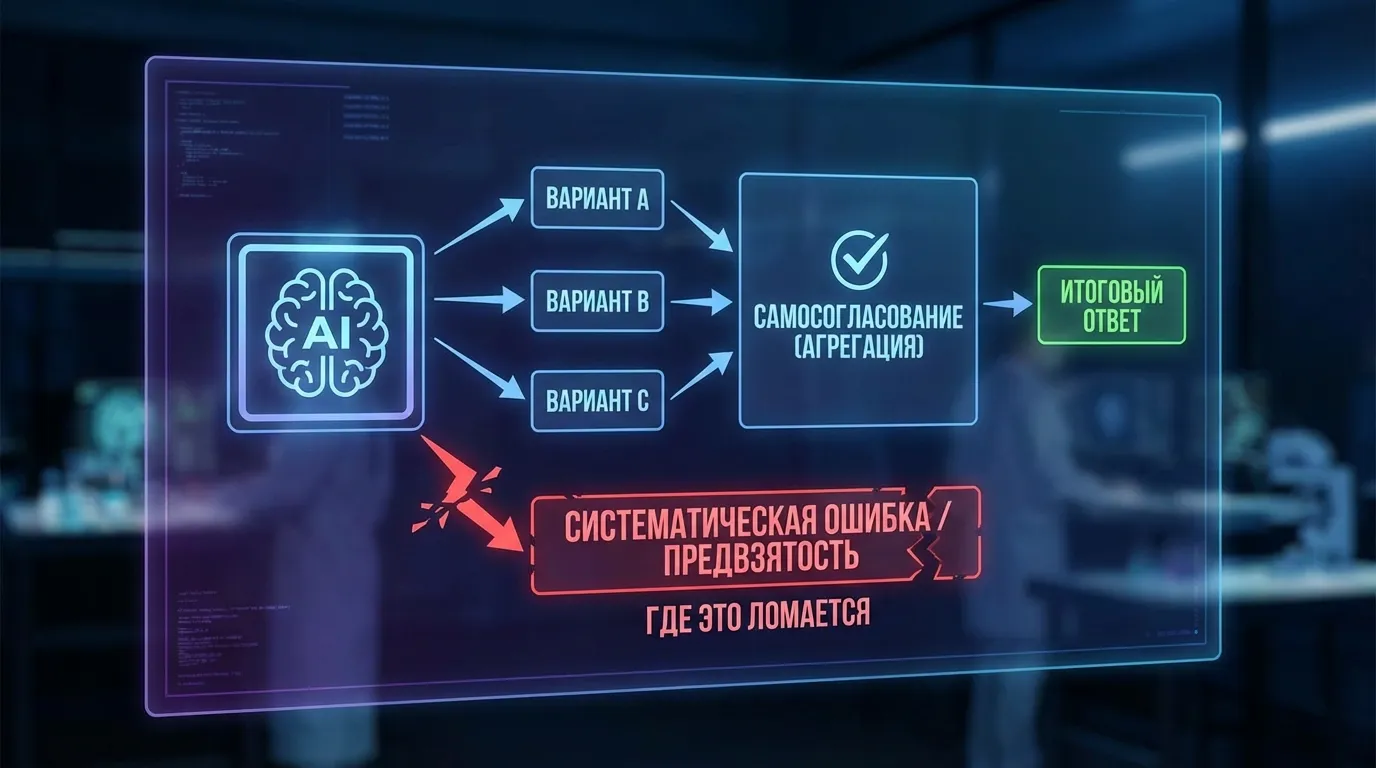
Представьте трюк из жизни: вы не доверяете первому попавшемуся ответу, поэтому делаете себе 10 черновиков в стол. Примерно так и работает self-consistency. Мы просим модель решить одну и ту же задачу несколько раз, но каждый раз как бы в другом «настроении»: где-то она будет чуть смелее, где-то осторожнее, где-то уйдёт в длинные рассуждения, а где-то срежет углы. В итоге у нас не один ответ, а пачка вариантов.
Дальше — самое человеческое: мы не пытаемся понять, какой из черновиков “красивее”. Мы просто смотрим, какой итог встречается чаще, и выбираем его. Логика простая: многие ошибки у модели случайные — типа “споткнулась”, перепутала знак, не туда свернула в середине. А правильный ответ, если задача более-менее определённая, обычно всплывает снова и снова. Поэтому голосование часто вытаскивает нас из мелких фейлов без всякой магии.
Это как спросить дорогу у 10 прохожих: один махнёт рукой “туда!”, второй вообще перепутает улицы, третий начнёт объяснять через парк, но если семеро показывают в одну сторону — скорее всего, туда и надо идти. Хотя, да, бывает и так, что “большинство” уверенно ведёт не туда: например, если вопрос хитрый, двусмысленный или все дружно опираются на одну и ту же популярную, но неверную идею.
Как заставить модель перепроверять себя на практике: рецепт без магии
Если отбросить красивые слова, self-consistency — это «пусть модель решит задачу несколько раз, а потом мы проголосуем». Работает удивительно часто, особенно на задачах с одним правильным ответом (арифметика, логика, простые выводы).
-
Просим решить задачу пошагово.
В промпте прямо говорим: «Решай пошагово, не перескакивай, в конце дай финальный ответ одной строкой:Ответ: …». Нам важно, чтобы модель реально проделала работу, а не выстрелила первой пришедшей в голову цифрой. -
Генерируем несколько независимых попыток (обычно 5–20).
Технически это просто N запусков одного и того же запроса, но с temperature > 0 (например, 0.7–1.0) и иногда с разными seed. Вот тут и нужна «случайность»: она заставляет модель сходить разными тропинками рассуждений, а не копировать один и тот же ответ. И да, независимость важна: если вы во втором прогоне показываете первый результат или просите «поправь себя», попытки начинают заражать друг друга, и голосование превращается в фикцию. -
Собираем только финальные ответы.
Не надо пытаться «склеивать» цепочки рассуждений. Берём из каждой попытки только последнюю строку вродеОтвет: 42. Всё остальное — шум (и часто ещё и риск утечки лишнего текста). -
Выбираем самый частый (majority vote).
Представьте урну с бюллетенями: каждый прогон — это бюллетень с одной цифрой/вариантом. Высыпали 10 бюллетеней на стол и считаете:
-
42 — 6 раз
-
41 — 3 раза
-
44 — 1 раз
Значит, берём 42. Без мистики: если ошибка случайная, она обычно «размазывается», а правильный ответ чаще всплывает как мода распределения.
Где это реально спасает: задачи, у которых есть один правильный ответ
Self-consistency реально выручает там, где у задачи есть один правильный ответ, и любая ошибка — это просто «съехал где-то на шаге». Типичный бытовой пример: вы считаете скидку и налог. Скажем, корзина на 3 990 ₽, скидка 15%, потом НДС 20%. Одна траектория модели может перепутать порядок (сначала налог, потом скидка) или округлить не там — и улететь. А если попросить 10–15 независимых расчётов, то большинство обычно повторит один и тот же итог, потому что математика тут как рельсы: либо ты доехал, либо нет. Ошибки, наоборот, «размазываются» — они разные и реже совпадают между собой.
Ещё классная зона — проверки на внимательность: единицы измерения, проценты, километры/мили, ватт-часы/киловатт-часы. Например, «потребление 800 Вт, работает 3 часа, сколько кВт⋅ч?» Тут правильный ответ буквально один (2,4 кВт⋅ч), а самые частые косяки предсказуемы: забыли поделить на 1000, перепутали Вт и Вт⋅ч, где-то потеряли час. Когда модель прогоняет несколько вариантов, большая часть путей всё равно приходит к одной и той же размерности и числу — и majority voting вытаскивает вас из случайной опечатки в рассуждении.
И, наконец, школьная алгебра/логические задачки — прям родная стихия. «Реши 2(x−3)=14» или «найди ошибку в доказательстве/в решении» — там ответ должен сойтись к конкретному x=10 или к конкретному месту, где нарушено правило. Один раз модель может “забыть” раскрыть скобки или неправильно перенести знак. Но если дать ей 8–20 попыток, то правильная цепочка обычно встречается чаще, просто потому что корректные шаги более стабильны: их меньше способов сделать неправильно так, чтобы в итоге случайно совпало. Поэтому тут self-consistency — не магия, а такой грубый, но рабочий способ заставить ответ «сойтись» к одному значению через большинство.
Где всё ломается: когда большинство — не умнее, а просто громче
Self-consistency звучит как «пусть модель перепроверит себя десять раз и выберет самое частое». И иногда это реально работает. Но есть ситуации, где большинство — не про ум, а про шум. Как если бы 10 человек в компании дружно повторили один городской миф («не ешь после шести — точно похудеешь»), потому что он звучит правдоподобно. И чем увереннее они кивают, тем сложнее заметить, что там вообще-то ерунда.
Первая поломка — размытые вопросы без единственного правильного ответа. Попросите: «посоветуй, как пережить выгорание», «перепиши текст в стиле Хемингуэя», «набросай эссе о свободе». Тут не за что голосовать: ответы могут быть разными и все по-своему нормальные. В результате majority vote выбирает не «лучший», а просто самый типичный вариант — безопасный, гладкий, местами скучный. Скажем, из 10 попыток 6 окажутся вариациями на тему «сон, спорт, терапия», и именно это “победит”, хотя вам мог быть нужен острый, нестандартный угол или конкретика под вашу ситуацию.
Вторая — «общая слепая зона». Self-consistency предполагает, что ошибки случайны и взаимно гасятся. Но у модели бывают систематические перекосы: она стабильно путает причину и следствие, уверенно “додумывает” факты, или каждый раз делает одну и ту же логическую подмену. Тогда большинство не исправляет ошибку, а цементирует её. Например, если модель в 7 из 10 прогонов одинаково неправильно интерпретирует условие задачи или уверенно приписывает цитату «Эйнштейну», голосование скажет: «значит, так и есть». И вот вы получили не проверку, а усилитель одной и той же галлюцинации.
Третья — цена и задержка. Десять попыток — это буквально десять генераций. Даже если одна занимает 2–3 секунды, вы внезапно превращаете быстрый ответ в ожидание на 20–30 секунд (или в более сложной задаче — ещё дольше). По деньгам то же самое: 5–20 сэмплов = 5–20× больше токенов. В реальном продукте это начинает ощущаться очень быстро: вроде бы хотели «надёжнее», а получилось «медленнее и дороже», причём без гарантий, что эта надёжность вообще выросла именно в вашем типе задач.
Как пользоваться без самообмана: маленькие страховки и здравый смысл
Я включаю self-consistency не “на всякий случай”, а когда цена ошибки ощутимая или задача реально хрупкая: расчёты, логика, сравнение вариантов, любые «если… то…», где легко перепутать знак, единицы или допущение. Для простых фактов и бытовых советов — чаще не надо, там быстрее поймать галлюцинацию другим способом (проверкой источника), чем гонять 20 сэмплов.
По числу попыток у меня простое правило: 5 — базовый режим, 10 — если ответ важный, 20 — если это уже почти “проверка перед публикацией”. И я всегда смотрю не только на победивший вариант, но и на распределение голосов. Если голоса распределились 2‑2‑1 — это не победа, это тревожная сирена. Вообще, любые “тонкие” победы (3‑2 при пяти) для меня = ответ неустойчивый. А если модель выдаёт 4–5 разных чисел/формулировок, значит, она сама не понимает, где сто́ит.
Что я делаю, когда вижу неустойчивость:
-
Переформулирую задачу: добавляю конкретику, убираю двусмысленность, прошу явно перечислить допущения (что считаем известным, что игнорируем).
-
Ставлю ограничители: “ответ в диапазоне?”, “может ли быть отрицательным?”, “проверь размерность/единицы (м, км, %, руб/мес)”, “сойдётся ли с крайними случаями”.
-
Прошу контрпример или стресс‑тест: “придумай пример, где твой ответ ломается”, “что должно быть верно, чтобы решение работало?”.
-
Подключаю внешний факт‑чек: справочник, калькулятор, поиск по источникам, маленький скрипт. Если это факт (дата, закон, цифра) — self-consistency не спасает, нужна верификация снаружи.
И ещё мелочь, но она реально помогает: я прошу модель в конце сделать быструю sanity‑check проверку в одну строку — “похоже ли число на реальность, если прикинуть на пальцах?”. Иногда это ловит те самые ошибки уровня “перепутал часы и минуты”, которые никакое голосование не считает проблемой.
Решайте любые задачи с помощью ИИ — от генерации текста до создания изображений и видео.
Текст и код
Генерация контента, перевод, анализ данных и автодополнение кода.
Изображения, видео и музыка
Создание иллюстраций, видеоконтента и уникальных треков любого жанра.
Диаграммы, графики и схемы
Визуализация данных, построение графиков и генерация блок-схем.
Личный кабинет
-
Приоритетная обработкаЗапросы от пользователей личного кабинета обрабатываются в первую очередь
-
Бонус за регистрациюСтартовый бонус на счёт личного кабинета (~20 запросов), без регистрации - 3 запроса
-
Все передовые нейросетиВ личном кабинете представлен широкий выбор нейросетей (120+).
-
Генерация реалистичных изображенийMidjourney 6.0, Stable Diffusion XL, Dall-E 3, Playground v2.5, Flux.1 Schnell, Flux.1 Dev, Flux.1 Pro, Flux.1.1 Pro, Kolors, Recraft v3, GPT Image 1 (low), GPT Image 1 (medium), GPT Image 1 (high), Google: Nano Banana, Google: Nano Banana Pro, FLUX.2 Flex, FLUX.2 PRO, FLUX.2 MAX, Google: Nano Banana 2
-
Создание музыкиНейросеть Suno создает музыку на основе вашего текста
-
Нет ограничения на количество символовБез регистрации вы можете отправить запрос не более 1000 символов
-
Работа с файламиПоддержка всех популярных форматов: pdf, excel, word, powerpoint, odt, c, js, php, py, html, sql, xml, yaml, markdown, txt, json, csv, png, jpeg и другие
-
Удобный вспомогательный чатНа всех страницах проекта, для получения быстрых ответов
