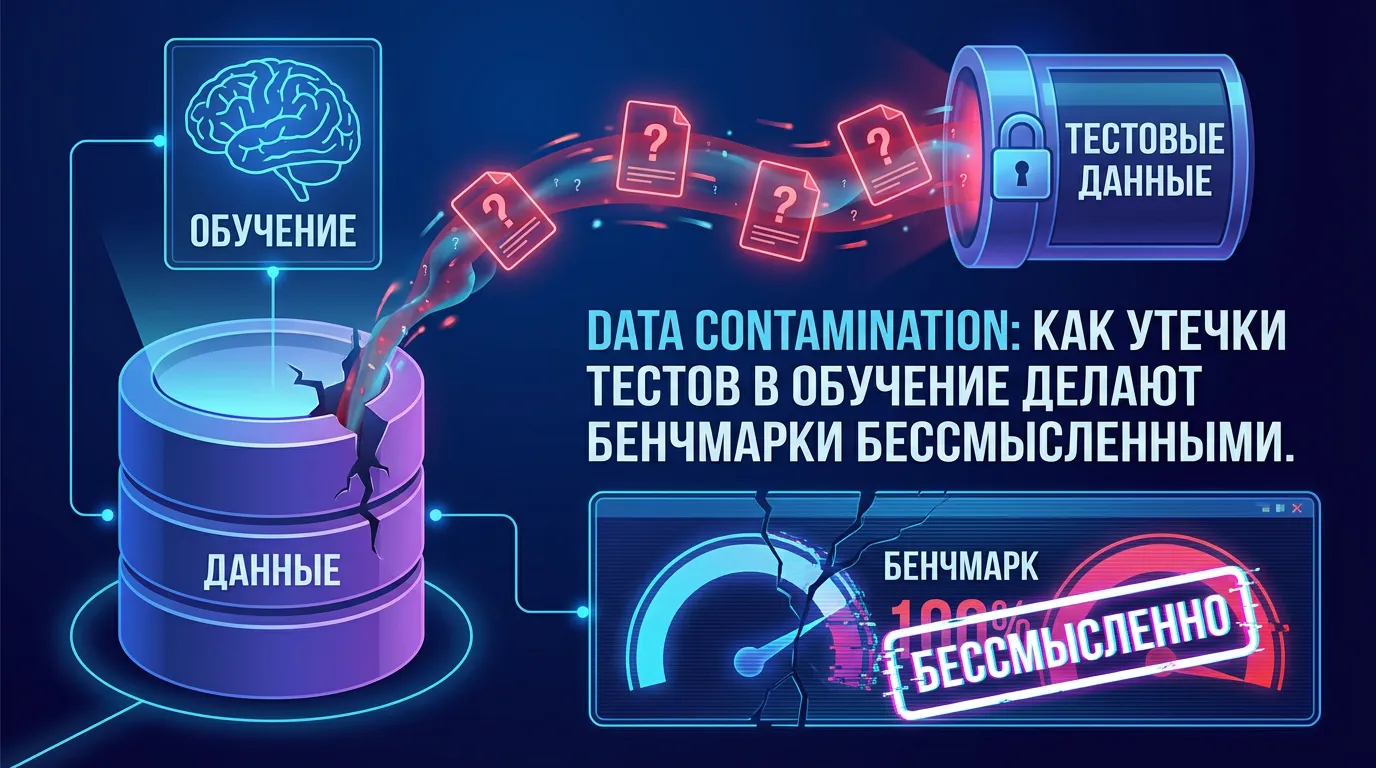
Что такое контаминация данных в машинном обучении?
- Экзамен, где половина класса уже видела ответы
- Как «вопросы из контрольной» оказываются в учебнике: три бытовых сценария утечки
- Почему таблицы лидеров начинают врать (и врут уверенно)
- Следы на месте преступления: как заподозрить контаминацию без лаборатории
- Как делают «чистые экзамены» и почему это дорого (но окупается)
- Что спрашивать у тех, кто продаёт вам “самую умную модель”: чек на честность
Экзамен, где половина класса уже видела ответы
Заходишь в очередной «рейтинг ИИ», как в таблицу медалей после олимпиады. У одного — рекорд, у другого — ещё рекорднее, графики вверх, фанфары, «модель обошла всех». И всё бы ничего, но через пару ссылок и сноску, спрятанную где-то внизу, начинается мини-детектив: а что если часть вопросов… была в учебнике заранее? Не в смысле «похожих», а прямо тех самых. И ты такой: стоп, а это вообще экзамен или репетиция с ответами?
Вот это и есть data contamination — когда тестовые задания, на которых модель должны честно проверять, случайно (или не очень) попадают в её обучение. Модель потом выходит на «контрольную», видит знакомую формулировку и не решает задачу, а вспоминает. Почти как слитые ответы на ЕГЭ: ты можешь набрать 90+, но это не значит, что ты внезапно стал сильнее в математике. Это значит, что контрольная перестала быть контролем.
И самое неприятное — из-за этого рушится доверие к любым «топам» и обзорам. Потому что рейтинг превращается в олимпиаду, где победителя выбирают не по знаниям, а по тому, у кого шпаргалка лучше и толще. А мы потом спорим в комментариях, какая модель «умнее», хотя на деле меряем, кто удачнее наткнулся на утёкшие вопросы.
Как «вопросы из контрольной» оказываются в учебнике: три бытовых сценария утечки
1) Контрольную просто выложили, и она разошлась по интернету.
Бенчмарк публикуют «для прозрачности», чтобы все могли сравнивать модели. А дальше он живёт своей жизнью: кто-то копирует в репозитории, кто-то пересказывает в блогах, кто-то делает разборы с готовыми ответами. Проходит полгода — и это уже не аккуратный тестовый набор, а такой общеизвестный сборник «вопросов с решениями», который встречается на каждом углу.
2) Данные собирали “пылесосом” со всего веба — и втянули тесты вместе со всем остальным.
Большие модели учат на огромных массивах текста, и сбор часто выглядит как гигантский пылесос, который втягивает и мусор, и ключи от сейфа. Он не различает, где учебный материал, а где “контрольная для проверки”. Если на сайте лежали тестовые вопросы или обсуждения с ответами — они улетят в общий мешок так же легко, как новости или форумы.
3) Вопросы чуть переформулировали, но смысл и ответы остались узнаваемыми.
Иногда кажется: “Ну мы же изменили формулировку, всё честно”. А по факту поменяли слова местами, добавили пару деталей — и всё. Если структура задачи та же, числа те же или ответ выводится тем же способом, модель может узнать это как знакомую песню по двум нотам.
И важный момент: утечка чаще не про злой умысел. Это побочный эффект масштаба и скорости — когда данных много, людей мало, а кусочки интернета перепутаны так, что даже сильная команда может не заметить, что “вопросы из контрольной” давно уже в учебнике.
Почему таблицы лидеров начинают врать (и врут уверенно)
Таблицы лидеров начинают врать ровно в тот момент, когда бенчмарк незаметно попадает в обучение. И дальше всё выглядит «научно»: аккуратные проценты, красивые +3, +5 баллов, уверенный отрыв от конкурентов. Только это уже не соревнование “кто лучше думает”, а соревнование “кто лучше помнит”. Модель не решает задачу — она её узнаёт. Как будто ей подсовывают тест, который она уже видела, пусть даже мельком, где-то в гигантском датасете.
Разница на бытовом уровне простая. “Вспомнить” — это когда ты видел конкретный вопрос и где-то внутри лежит готовая связка “вопрос → ответ”. Почти как автодополнение. “Понять/обобщить” — когда ты видишь новую формулировку, новый пример, немного другой контекст, и всё равно собираешь решение из смысла, а не из памяти. Это как отличать человека, который выучил один билет, от человека, который реально понимает тему и может объяснить её по-разному.
Мини-сцена, которая это отлично показывает. Представьте: человек блестяще сдаёт экзамен по старому билету — отвечает слово в слово, без запинок, преподаватель доволен. А потом вы спрашиваете то же самое, но другими словами: “Окей, а если ситуация чуть меняется… почему это работает?” И всё, ступор. Он не тупой, просто он не решал, он воспроизводил. С утечкой в ML то же самое: бенчмарк становится набором “старых билетов”, и модель выглядит умной ровно до тех пор, пока вы не перефразируете вопрос или не перенесёте задачу в реальный, чуть более грязный мир.
Вот почему читателю полезно перестать слепо верить цифрам. Если данные протекли, то +5 баллов иногда означает не “модель стала умнее”, а “модель стала лучше угадывать знакомое”. И в лидерборде это выглядит как прогресс, а на практике — как разочарование: чуть меняешь формулировку, и магия пропадает.
Следы на месте преступления: как заподозрить контаминацию без лаборатории
Есть такой странный эффект: модель отвечает на «популярные» вопросы слишком ровно, слишком гладко — как будто читает с листа. Те же формулировки, те же примеры, иногда даже узнаваемые куски из известных разборов. Спросите её про классическое “объясни backprop” или “что такое P=NP” — и всё звучит идеально. А потом даёте чуть более жизненную задачу (письмо клиенту, спорный кейс, кусок грязных данных), и внезапно начинается каша. Это один из самых бытовых признаков: блестит там, где блестеть легко, и теряется там, где нужно реально думать, а не вспоминать.
Второй след — резкое падение качества при мелких изменениях. И тут работает мой любимый приём: поменяй порядок слов — и посмотри, не исчезнет ли волшебство. Перефразируйте вопрос, переставьте условия местами, замените числа на другие, попросите тот же ответ, но «объясни так, будто я ошибся в предпосылке». Если модель была натренирована на конкретной формулировке, она часто “ломается” неожиданно грубо: уверенность остаётся прежней, а смысл утекает. Причём ломается не как человек (с оговорками, сомнениями), а как автозаполнение — было совпадение шаблона, стало меньше совпадения, и всё.
Третий момент — аномально высокая точность на одном тесте при общей посредственности в демо и живых задачах. В обзорах это выглядит как магия графиков: на бенчмарке +10 пунктов, а в реальных примерах — ну, нормально, как у всех. Такое несоответствие само по себе ничего не доказывает, но это классический повод насторожиться: почему именно этот тест модель «любит» больше остальных? Ещё подозрительнее, когда авторы показывают один-два блестящих набора метрик, а на неудобные сценарии уходят в туман: “тут сложно оценивать”, “нужны дополнительные исследования”, и т.д.
И последнее — обращайте внимание на повторяемость. Если вы несколько раз гоняете близкие по смыслу запросы, а ответы подозрительно похожи на заученный эталон (одни и те же тезисы, одинаковая структура, одинаковые “умные” оговорки), это тоже улика. Читателю не нужна криминалистика уровня «сравнить хэши датасетов». Достаточно развить чутьё: не влюбляться в красивую цифру, смотреть на поведение, и обязательно проверять простыми трюками вроде перестановки слов. Потому что магия графиков заканчивается ровно там, где начинается реальная работа.
Как делают «чистые экзамены» и почему это дорого (но окупается)
«Чистый экзамен» для модели — это не когда вы нашли “правильный” файл с вопросами и один раз прогнали прогон. Это скорее экзамен под надзором, где задания не валяются в коридоре заранее. Самая понятная картинка: запечатанный конверт с задачами, который вскрывают только в день экзамена. Пока конверт закрыт, никто — ни модель, ни команда, ни случайные утечки в интернете — не может “подучить ровно это”. Вот почему нормальная оценка — это процесс: хранение, доступы, правила, повторные проверки. И да, это стоит денег и времени, но окупается тем, что цифрам потом вообще можно верить.
Что обычно делают на практике, по-человечески:
- Скрытые/приватные тесты: часть заданий видит только “экзаменационная комиссия”. Публично — максимум пример формата, а не сам экзамен.
- Свежие задания: задачи постоянно обновляют, как новые билеты каждый семестр. Даже если что-то утекло, оно быстро устаревает.
- Независимые проверяющие: не те же люди, что “натаскивают” модель. Иначе получается, как если тренер сам себе выставляет оценку.
- Много вариантов одной задачи: один смысл — десять формулировок. Чтобы нельзя было выехать на запоминании конкретной фразы.
- Проверка на перефразирования и реальные сценарии: задают вопрос по-разному и смотрят, не ломается ли ответ; плюс добавляют задачи “как в жизни” — с лишними деталями, неоднозначностью, маленькими подвохами.
Суть простая: хороший экзамен — это не бумажка с вопросами. Это система, где даже при желании сложно “подсмотреть”, а значит результат отражает умение, а не удачу или утечку.
Что спрашивать у тех, кто продаёт вам “самую умную модель”: чек на честность
Представьте переговорку. Вам показывают слайды, где «+7% к SOTA» и «топ‑1 на бенчмарке». Вы киваете, но держите в голове простую мысль: цифры — это не магия, это условия эксперимента. И вот вы включаете режим зануды (в хорошем смысле), потому что вам потом этим бюджетом отвечать.
Вы: Окей, а тест был публичным?
Вендор/подрядчик: Да, классический, все его знают.
Вы: Тогда второй вопрос: как вы гарантируете, что он не утёк в обучение? Есть проверка на совпадения, дедупликация, отчёт? Или «ну мы так не делаем»?
Вы: Прогон делали сами или есть независимые прогоны?
Вендор: Мы у себя запускали, всё честно.
Вы: А можно ссылку на репродуцируемый прогон: сид, версия модели, параметры, скрипт? И ещё — чтобы кто-то третий повторил, без вашего участия.
Вы: Проверяли ли на перефразировании и мелких вариациях?
Вендор: Там и так сложные вопросы.
Вы: Понял. Но если модель «знает» тест, то перефразирование обычно быстро снимает маску. Есть результаты на перефразах, перестановках, смене формата (таблица → текст), добавлении лишнего контекста?
Дальше — самое важное, то, что обычно пытаются объехать:
Вы: Можно ли дать наши задачи? Не «похожие», а прям наши: письма клиентов, тикеты, типовые ошибки операторов, ваши же регламенты.
Вендор: Ну, NDA, данные, сложно…
Вы: Окей, давайте обезличим. Или дадим синтетику, но по нашему шаблону. Мне нужен пилот на нашей реальности, а не на олимпиаде.
И тут, честно, моя любимая реплика из жизни: «Покажите не рекорд на олимпиаде, а как оно отвечает на письма от наших клиентов в пятницу вечером».
Если хотите прям короткий чек‑лист вопросов, чтобы защищать ожидания и бюджет:
-
Что именно мерили? (качество, стоимость на 1k токенов, задержку, стабильность)
-
Тест публичный или приватный? Если публичный — что делали против утечки в обучение?
-
Есть ли независимый прогон и воспроизводимость (код/параметры/версии)?
-
Есть ли стресс‑тесты: перефразирование, шум, длинный контекст, «вредные» подсказки, смена формата?
-
Можно ли прогнать наши кейсы (хотя бы 50–200 примеров) и увидеть не среднюю температуру, а реальные фейлы?
-
Что с ошибками? Покажите 10 худших ответов, а не 10 лучших.
-
Как будет выглядеть мониторинг в проде: дрейф, деградация, алерты, переоценка качества?
Смысл этого допроса простой: вы не придираетесь. Вы покупаете не «оценку на бенчмарке», а инструмент, который либо разгрузит команду и улучшит сервис, либо красиво провалится после первой же недели в проде. И лучше выяснить это на переговорах, а не на счетах и жалобах клиентов.
Решайте любые задачи с помощью ИИ — от генерации текста до создания изображений и видео.
Текст и код
Генерация контента, перевод, анализ данных и автодополнение кода.
Изображения, видео и музыка
Создание иллюстраций, видеоконтента и уникальных треков любого жанра.
Диаграммы, графики и схемы
Визуализация данных, построение графиков и генерация блок-схем.
Личный кабинет
-
Приоритетная обработкаЗапросы от пользователей личного кабинета обрабатываются в первую очередь
-
Бонус за регистрациюСтартовый бонус на счёт личного кабинета (~20 запросов), без регистрации - 3 запроса
-
Все передовые нейросетиВ личном кабинете представлен широкий выбор нейросетей (120+).
-
Генерация реалистичных изображенийMidjourney 6.0, Stable Diffusion XL, Dall-E 3, Playground v2.5, Flux.1 Schnell, Flux.1 Dev, Flux.1 Pro, Flux.1.1 Pro, Kolors, Recraft v3, GPT Image 1 (low), GPT Image 1 (medium), GPT Image 1 (high), Google: Nano Banana, Google: Nano Banana Pro, FLUX.2 Flex, FLUX.2 PRO, FLUX.2 MAX, Google: Nano Banana 2
-
Создание музыкиНейросеть Suno создает музыку на основе вашего текста
-
Нет ограничения на количество символовБез регистрации вы можете отправить запрос не более 1000 символов
-
Работа с файламиПоддержка всех популярных форматов: pdf, excel, word, powerpoint, odt, c, js, php, py, html, sql, xml, yaml, markdown, txt, json, csv, png, jpeg и другие
-
Удобный вспомогательный чатНа всех страницах проекта, для получения быстрых ответов
